Microsoft certifications. I am a hands-on architect with proven 19+ years of experience in architecting, designing, and developing distributed software solutions for large enterprises. At Microsoft, as a Principal Software Engineering Manager, I own the Platform team. I see software development as a craft, and I am a big proponent of software architecture and clean code discipline-n-practices. I like to see the bigger picture and make a broader impact. I was also a Microsoft MVP for the past 7 years on Visual Studio and Dev Technologies
April 30th, 2021 | Posted by Vidya Vrat in Test - (0 Comments)
Life often throws choices upon us, and many times we have a hard time decide, and make a good choice. This becomes very critical especially when we make an important decision.
There are four villains of decisive decision-making.
CAP stands for Consistency, Availability and Partition tolerance. The CAP theorem first appeared in autumn 1998 and published as the CAP principle in 1999 also named Brewer’s theorem after computer scientist Eric Brewer states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
Consistency: Every read receives the most recent write or an error
Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
The only exception which can practically demonstrate all CAP would be a single node system, which can’t be regarded as a distributed system. Moreover, it can’t scale to the level of what a distributed system is capable of and designed with a goal in mind.
Note: Single node can utilize only Scale-Up or Vertical-Scaling strategy. Any system which is using Scale-Out or Horizontal-Scaling has to abide by the CAP theorem.
Explanation
No distributed system is safe from network failures, thus network partitioning has to be tolerated. In the presence of a partition, one is then left with two options: consistency or availability. When choosing consistency over availability, the system will return an error or a time out if particular information cannot be guaranteed to be up to date due to network partitioning.
When choosing availability over consistency, the system will always process the query and try to return the most recent available version of the information, even if it cannot guarantee it is up to date due to network partitioning (which is better in many cases for user experience). When a network connection is established, consistency will be achieved again across nodes/partitions i.e. eventually consistent.
Database systems designed with traditional ACID guarantees in mind such as RDBMS choose consistency over availability, whereas systems designed around the BASE philosophy, common in the NoSQL databases, for example, choose availability over consistency.
CAP in Practice
Let’s say you are designing a distributed system that has a cluster of 4 data nodes. Replication factor is 2 i.e. any data written in the cluster must be written on 2 nodes; so when one goes down – second can serve the data.
Now try to apply CAP theorem on this requirement. Remember, in a distributed system, two things may happen anytime i.e. node failure (hard disk crash, EC2/VM failure) or network failure (the connection between two nodes go down) [Fallacy of distributed computing].
CP [Consistency/Partition Tolerance] Systems
Distributed systems ensure data consistency at the time of reading the data, by a voting mechanism, where all nodes who have a copy of data mutually agree that they have “same copy” of requested data. Now let’s assume that requested data is present in two nodes A-1 and A-2. The client tries to read the data; and our CP system is partition tolerant as well, so an expected network failure occurred and A-1 is detected as down. Now the system cannot determine that A-2’s data copy is the latest or not; it may be stale as well. So the system decides to send an error to the client.
Here system chose to prefer data consistency over data availability. Similarly, at the time of writing the data if the replication factor is 2, then the system may reject write requests until it finds two healthy nodes to write data fully in consistent manner. Hence, now the system is considered not “Available” i.e CAP’s “A” is sacrificed.
CP system is harder and expensive to implement.
AP [Availability/Partition Tolerance] Systems
In today’s customer-obsessed mindset, a system is expected to up-and-running 24×7 hence, you have to put proper thinking in place and make informed decisions while choosing trade-offs. As with CP, the system is known not to be “Available” in the event of a failure.
A resilient system design would rather consider instead of sending ERROR (in case A-1 is down); it sends the data received from A-2. Chances are that the data client will get may not be the latest data (hard to decide). Hence, now the system is considered “Available” i.e CAP’s “C” is sacrificed.
CA [Consistency/Availability] Systems, Really?
In a distributed environment, we cannot avoid “P” of CAP. So we have to choose between CP or AP systems. If we desire to have a consistent and available system, then we must forget about partition tolerance and it’s possible only in non-distributed systems such as an RDBMS system.
Closing Note
CAP is frequently misunderstood as if one has to choose to abandon one of the three guarantees at all times. In fact, the choice is really between consistency and availability only when a network partition or failure happens; at all other times, no trade-off has to be made.
CAP is to choose your tradeoff in the event of a failure (network/node). In the absence of network failure – that is, when the distributed system is running normally – both availability and consistency can be satisfied.
In today’s world, we can achieve all 3 in a distributed system (if not fully, then partially at least). E.g. Tunable consistency in Cassandra
Those days are gone when an enterprise was happily serving its customers by just a handful of on-prem servers, delivering content within seconds to minutes, thinking hours of downtime for maintenance and deployment is fine and data consumption is in gigabytes.
Today’s distributed systems are meant to serve an ever-expanding number of customers “Anytime, Anywhere, on Any Device“, customers expecting a response in milliseconds and 100% uptime. Users expect millisecond response times with 100% uptime, and data is measured in Petabytes.
Today’s demands are simply not met by yesterday’s software architectures.
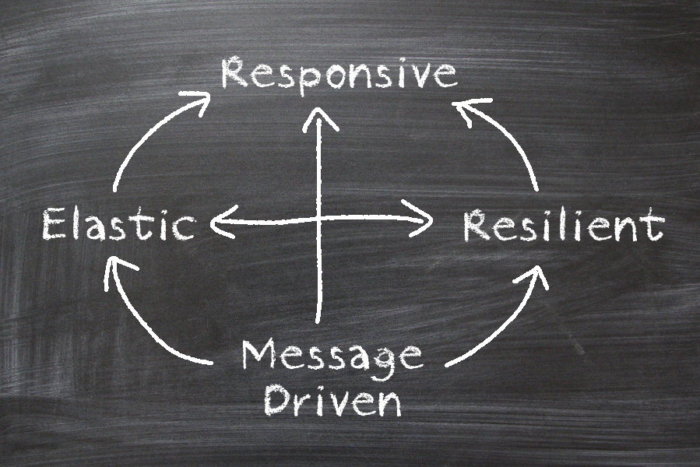
To meet such enlarged expectations, our distributed systems must be Responsive, Resilient, Elastic and Message Driven, and this is called a Reactive System. Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than a disaster.
Four Reactive Principles
Responsive: The system responds in a timely manner if at all possible. Responsiveness is the cornerstone of usability and ensuring early problem detection and resolution. Responsive systems focus on providing rapid and consistent response times and delivering consistent quality of service. This consistent behavior, in turn, simplifies error handling, builds end-user confidence, encourages and promotes continued interaction with the software application.
Resilient: The system stays responsive in the face of failure. Any system that is not resilient will be unresponsive after a failure. Microservice Architecture lays the foundation for building a resilient system. Resilience is achieved by isolation, replication, and containment, Failures are contained within each component, isolating components from each other and thereby ensuring that parts of the system can fail and self-heal without compromising the system as a whole.
Elastic: The system stays responsive under varying workloads and increased demands. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated and support the business continuity. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them.
Message Driven: The system relies on asynchronous message-passing to ensures loose coupling, isolation, location transparency, and provides the means to delegate errors as messages. Asynchronous messaging supports nonblocking communication which allows recipients to only consume resources while active, leading to less overhead on the system due to non-blocking I/O.
We all are living in the era of “Distributed Computing”, regardless of how simple it may appear from outside, it’s way over complicated under the hood. System Design approach must be not to fall in the trap of “8-Fallacies-Of-Distributed-Computing”. When I design and architect or even review, my favorite ones are to solve/look for the challenges related to #1, 2, 3, 4, 7, and 8 (however all are equally important). Which one grabs your focus when you design and architect? please comment, and I welcome your questions and/or suggestions. Image Credit – Denise Yu Twitter: https://lnkd.in/eJYnpCw
Cloud-native is an approach to build applications using microservices, containers, Kubernetes, DevOps, CI/CD, and cloud (public, private, hybrid). With this great combination of great architecture, platform, culture, dev practice, and cloud-computing model your applications will be built for scale, continuous change, fault-tolerant, and manageable. Let’s explore and understand each of the key players in the cloud-native approach.
Microservices
Microservice is a small autonomous, tightly scoped, loosely coupled, strongly encapsulated, independently deployable, and independently scalable application component. Microservice has a key role to play in distributed system architecture.
A container is a standard unit of software that packages up code and all its dependencies, so the application runs quickly and reliably from one computing environment to another. A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries, and settings. Containers provide an abstraction at the app layer that packages code and dependencies together.
Kubernetes (K8s)
Kubernetes was born from Google’s over 15-year experience running production workloads. It is designed to grow from tens, thousands, or even millions of containers. Kubernetes is a container runtime agnostic. Kubernetes is an open-source container orchestration tool designed to automate deploying, scaling, and operating containerized applications. “Distributed Management and Orchestration “of containers is an integral part of making your application cloud-native, and Kubernetes does it all.
DevOps
DevOps is NOT a “Packaged Solution”. I.e. You cannot buy and install it.
DevOps is the union of people, process, and products to enable continuous delivery of value to our end users.” – Donovan Brown, MSFT. DevOps is a “culture” (Agile is a mindset), where development, test, and operations work together in a collaborative manner to automate the delivery of quality software. DevOps culture develops a “production-first mindset”. I.e. applying DevOps ensures that your code is always ready to be deployed to production
DevOps breaks the wall of confusion between teams and fosters better communication and collaboration throughout the application development lifecycle and results in better visibility and small frequent deployments together.
Continuous Integration (CI) and Continuous Delivery (CD) enables and empowers any software delivery team in an organization to continuously deliver value to their end-users.
With CI/CD practices in place, development teams are more likely to commit code changes more frequently, which leads to better collaboration and software quality.
Continuous Integration (CI)
CI is the process through which the building and validation of developer code are automated to ensure quality check-ins. You can build a CI/CD pipeline in the DevOps tool of your choice, and for cloud-native it will not be complete unless you have an important step “push the image to container registry”. Here, is a visual of how CI phases look like in Azure DevOps (previously known as VSTS).
CD picks up the package built by CI, deploys those into multiple environments like Dev, QA, staging, etc. then runs various tests such as integration tests, performance tests, load test, etc. and if all works fine then on a button click it can be finally deployed into production.
Summary
While each of the above serves tremendous value in its own entity, but if all the above combined together then it will contribute towards a true cloud-native approach. Imagine using benefits of cloud, microservices, containers, Kubernetes, DevOps, CI/CD combined together, which unlocks the formula to the success of any organization that want to reap the multifold benefits to the health of software, delivering value to the customers, support demand at scale, and lowering the development and operational cost of the application.
If you are not cloud-native yet, then you may be interested in knowing that by 2025, over 80% of enterprise apps will become cloud-based (source: forbes.com) or be in the process of transferring themselves over to cloud-native apps. Are you?
On Sep 14, 2019, Saturday, I spoke at #SeattleCodeCamp (this was my 4th year in a row). Both of my sessions were unique in nature, simple to follow, and heavy on core concepts, and practical implementation. 1- Writing code with a product mindset. – Pigott Room #306 8:30-9:30am 2- Real-world examples of MicroService Architecture and Implementation. – Pigott Room #205 11-12pm This was a FREE Tech Community event available to be registered at https://lnkd.in/eM-tzVs
I am a hands-on architect with proven 19+ years of experience in architecting, designing, and developing distributed software solutions for large enterprises. At Microsoft, as a Principal Software Engineering Manager, I own the Platform team. I see software development as a craft, and I am a big proponent of software architecture and clean code discipline-n-practices. I like to see the bigger picture and make a broader impact. I was also a Microsoft MVP for past 7 years on Visual Studio and Dev Technologies I can be reached at vidya_mct@yahoo.com or twitter @dotnetauthor
























 I am a hands-on architect with proven 19+ years of experience in architecting, designing, and developing distributed software solutions for large enterprises. At Microsoft, as a Principal Software Engineering Manager, I own the Platform team. I see software development as a craft, and I am a big proponent of software architecture and clean code discipline-n-practices. I like to see the bigger picture and make a broader impact. I was also a Microsoft MVP for past 7 years on Visual Studio and Dev Technologies I can be reached at vidya_mct@yahoo.com or twitter @dotnetauthor
I am a hands-on architect with proven 19+ years of experience in architecting, designing, and developing distributed software solutions for large enterprises. At Microsoft, as a Principal Software Engineering Manager, I own the Platform team. I see software development as a craft, and I am a big proponent of software architecture and clean code discipline-n-practices. I like to see the bigger picture and make a broader impact. I was also a Microsoft MVP for past 7 years on Visual Studio and Dev Technologies I can be reached at vidya_mct@yahoo.com or twitter @dotnetauthor



